The Digital Benefits Network and Massive Data Institute Experiment with AI to Translate Public Benefits Policies into Software Code
Georgetown University’s Digital Benefits Network (DBN) at the Beeck Center for Social Impact + Innovation and Massive Data Institute (MDI) teams are among the first to extensively research how to apply a Rules as Code framework to the U.S. public benefits system. We draw on international research and examples, and have identified numerous U.S.-based projects that could inform a national strategy, along with a shared syntax and data standard.
On March 24, 2025, we released a new report, AI-Powered Rules as Code: Experiments with Public Benefits Policy, which documents four experiments exploring if artificial intelligence (AI) can be used to expedite the translation of policies into software code for implementation in public benefits eligibility and enrollment systems under a Rules as Code approach. We also offer a summary + key takeaways version.
To increase access for eligible individuals and ensure system accuracy, it is imperative to quickly build a better understanding of how generative AI technologies, in particular commercially-available large language models (LLMs), can, or cannot, aid in the translation and standardization of eligibility rules in software code for these vital public benefits programs. We see a critical opportunity to create open, foundational resources for benefits eligibility logic that can inform new AI technologies and ensure that they are correctly interpreting benefits policies.
We conducted initial experiments from June to September 2024 during the Policy2Code Prototyping Challenge. The challenge was hosted by the DBN and the MDI, as part of the Rule as Code Community of Practice. Twelve teams from the U.S. and Canada participated in the resulting Policy2Code Demo Day at BenCon 2024. We finished running the experiments and completing the analysis from October 2024 to February 2025. Our research team includes students, faculty, and staff from the DBN, MDI, and the Center for Security and Emerging Technology (CSET).

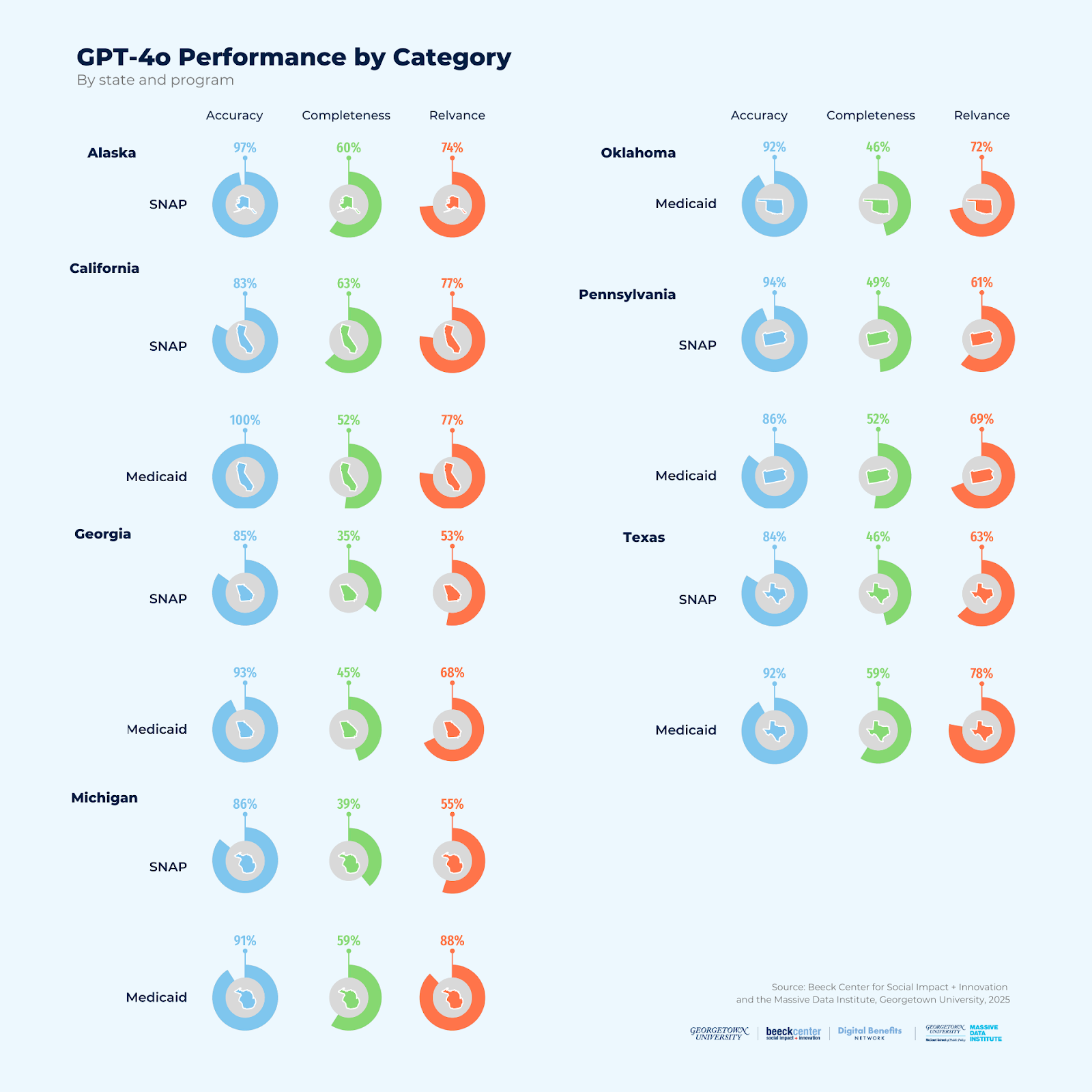
Our team experimented with multiple LLMs and methodologies to determine how well the LLMs could translate Supplemental Nutrition Assistance Program (SNAP) and Medicaid policies across seven different states. We found that LLMs are capable of supporting the process of generating code from policy, but still require external knowledge and human oversight within an iterative process for any policies containing complex logic.
Our experiments addressed the following questions:
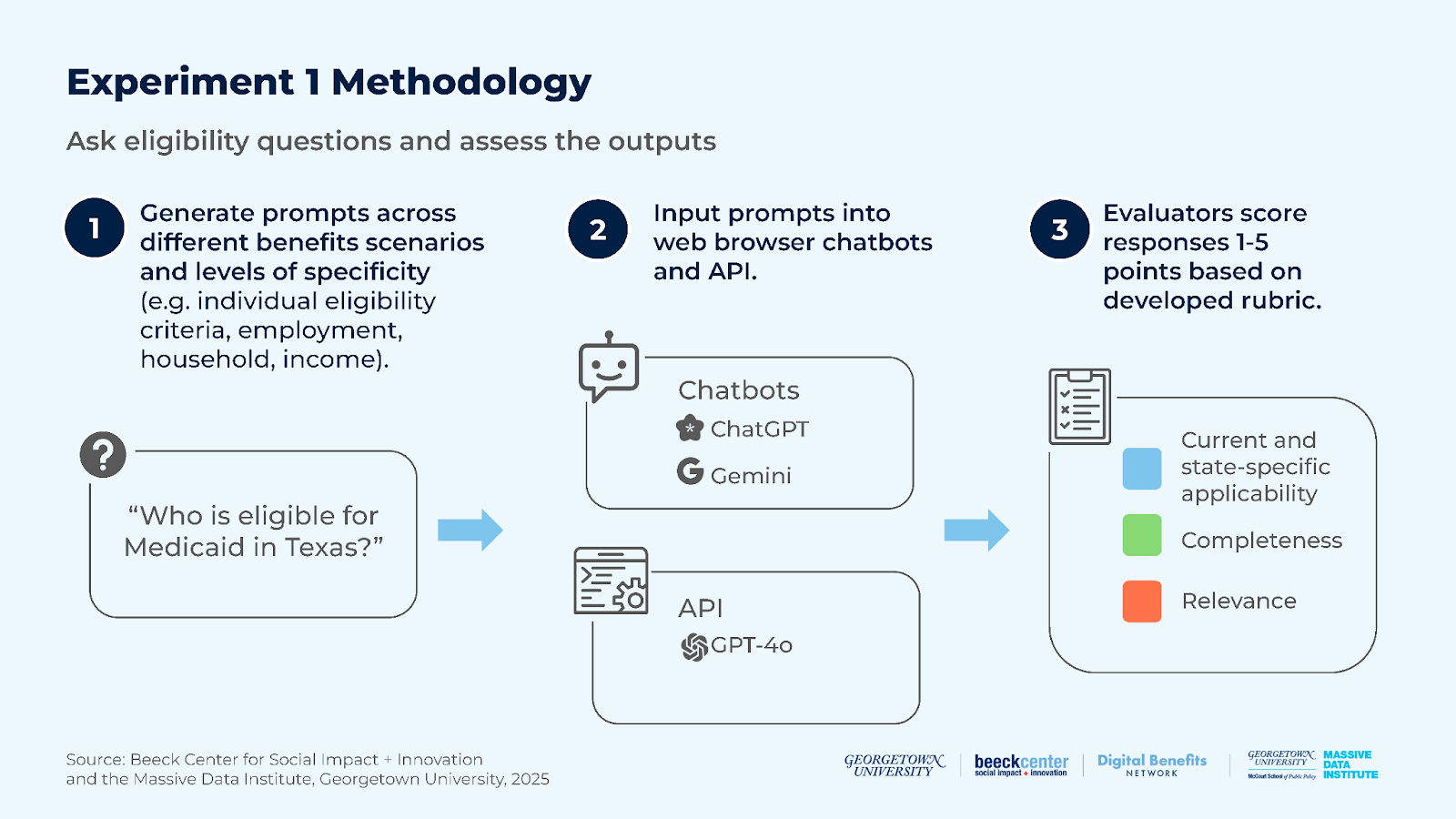
Experiment 1: How well can LLM chatbots answer general SNAP and Medicaid eligibility questions based on their training data and/or resources available on the internet? What factors affect their responses?
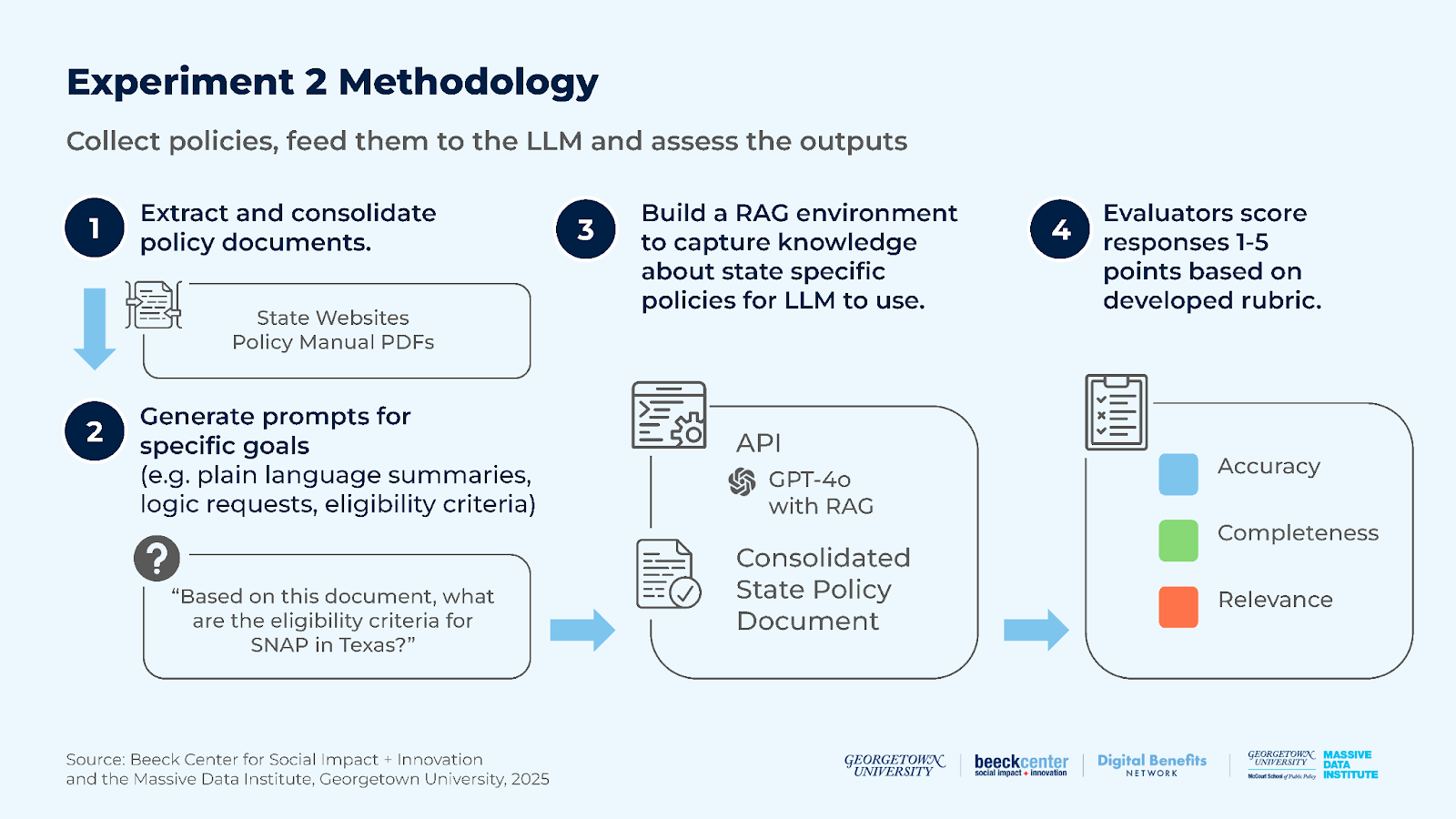
Experiment 2: How well can an LLM generate accurate, complete, and logical summaries of benefits policy rules when provided official policy documents?
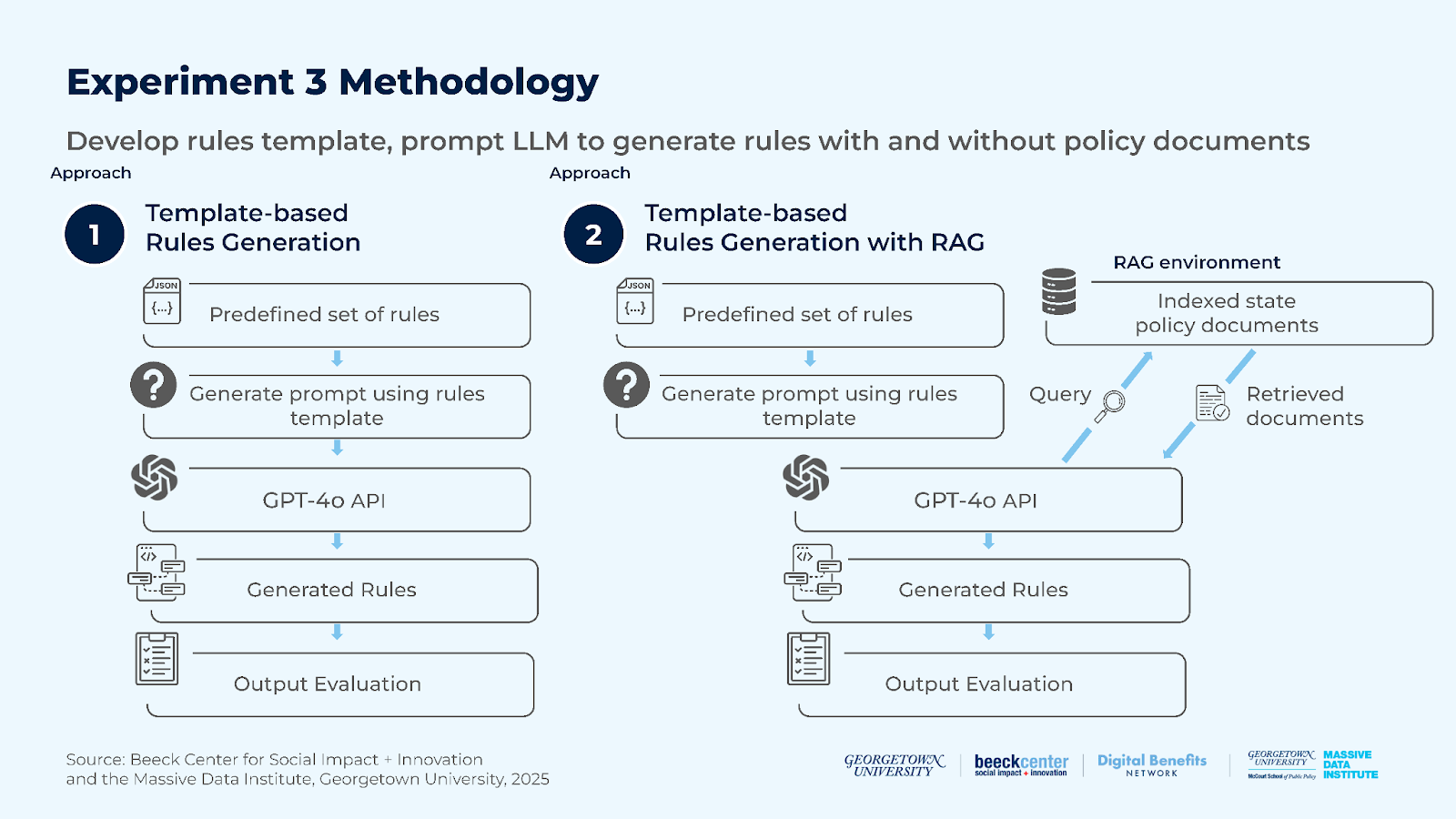
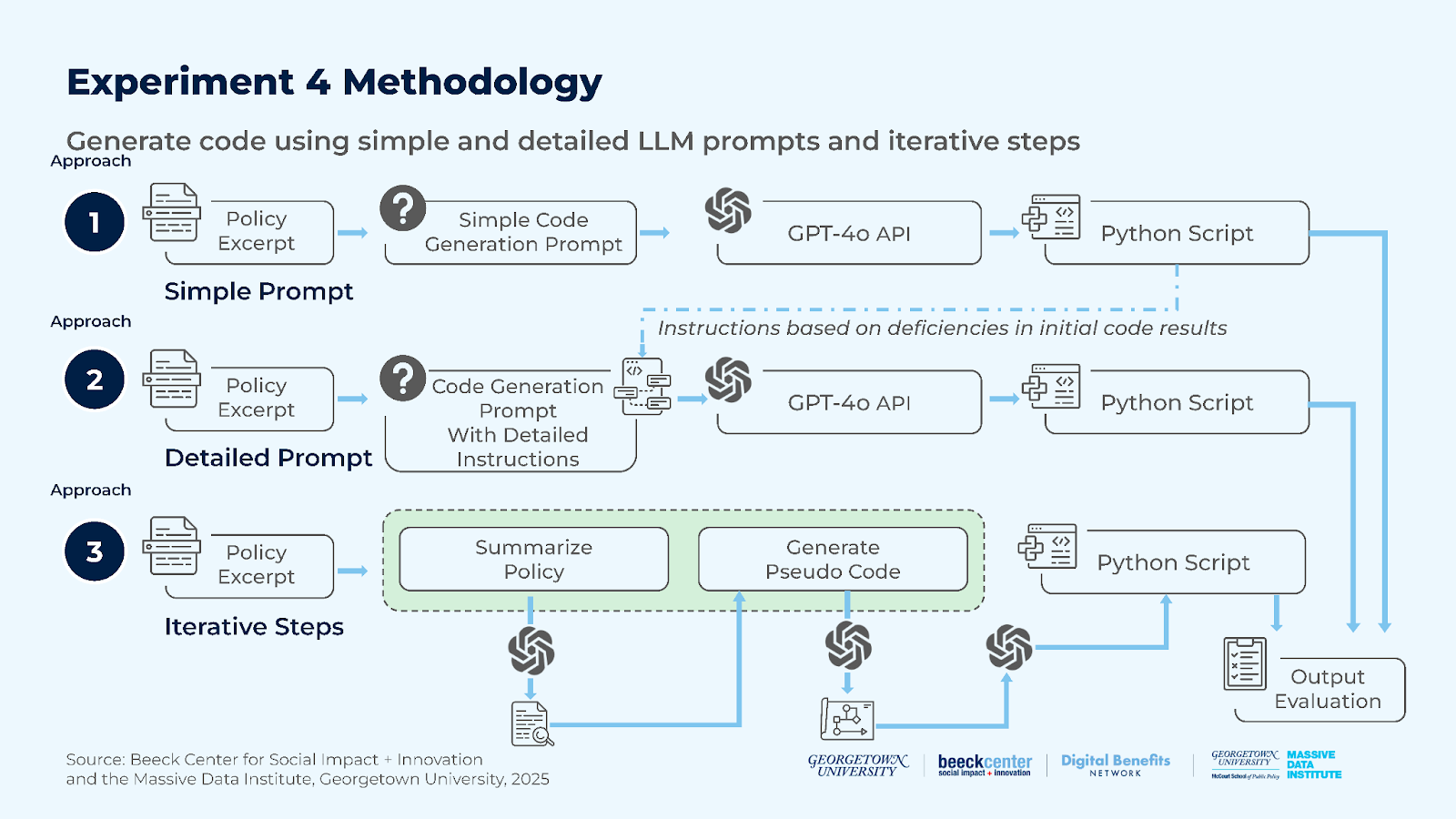
Experiment 4: How effectively can an LLM generate software code to determine eligibility for public benefits programs?
In the report and summary you will learn more about key takeaways including:
- LLMs can help support the Rules as Code pipeline. LLMs can extract programmable rules from policy by leveraging expert knowledge retrieved from policy documents and employing well-crafted templates.
- LLMs achieve better policy-to-code conversion when prompts are detailed and the policy logic is simple.
- State governments can make it easier for LLMs to use their policies by making them digitally accessible.
- Humans must be in the loop to review outputs from LLMs. Accuracy and equity considerations must outweigh efficiency in high-stakes benefits systems.
- Current web-based chatbots have mixed results, often risking incorrect information presented in a confident tone.
Ongoing Open Experimentation
We encourage ongoing, open experimentation to test the application of LLMs in public benefits eligibility and the development of Rules as Code. In the report, we offer ideas on how to repeat and build upon our experiments.
The report includes methodology details, results in tables and visualizations, and findings including considerations for public benefits use cases. Each experiment includes openly accessible materials in a linked appendix. We share the rubrics we developed to evaluate the accuracy, completeness, and relevance of the responses. Additionally, we share our prompts, responses, and scores.
Get in Touch
We’re eager to hear from you. This work, like any public-facing project, improves as more stakeholders offer their input. We welcome your thoughts, questions, or potential collaboration ideas. Email us at rulesascode@georgetown.edu.