Foundation of a Successful Data Project: Identify and Mitigating Bias
This blog is the fourth in an ongoing series by the State Chief Data Officers Network at the Georgetown Beeck Center reflecting the best practices and lessons learned by our cohort of participants in Data Labs. The Data Labs initiative helps states launch data-driven economic recovery projects as a result of the COVID-19 pandemic.
March 2, 2022 – By Carlos Andrés Arias
Mitigating data bias may be one of the most important factors in creating positive social change. Yet, it is often overlooked. Practitioners must develop complex data flows and governance frameworks that ensure data is collected, sourced, and processed using equitable methods. Taking these measures to make sure that data bias does not creep in and negate social change efforts is essential for ensuring good governance and protecting vulnerable populations.
In January 2022, Beeck Center Data Labs state teams worked on developing data governance frameworks to address this issue. The teams focused on mapping roles and responsibilities, clarifying data ownership roles, and forming data sharing agreements with key inter-agency stakeholders. Careful analysis of current data flows, ownership roles, and potential instances of bias inherent in data is central to this process.
State teams participated in a workshop that challenged them to scrutinize their data practices, rethink their perspective on how data is collected, and identify ways in which to reduce bias in their data sets.
Data Labs’ Five Principles for Mitigating Data Bias
Catherine Nikolovski, Executive Director of Civic Software Foundation, shared five principles that can guide state teams as they analyze their data practices to mitigate data bias.
- 1. All Data Are Created
- 2. Recognize Intersectional Systems
- 3. Mind the Gap
- 4. Unpack “Risk” and Center Impact
- 5. Algorithms Project Biases Into the Future
All Data Are Created
Data is not “objective” or neutral because bias can emerge throughout the data lifecycle, including why data is collected, how data is collected, and how that data is interpreted. The role of practitioners is to limit the ways that bias’ might surface throughout each stage of the data lifecycle.
Bias can emerge in each step of the data lifecycle:
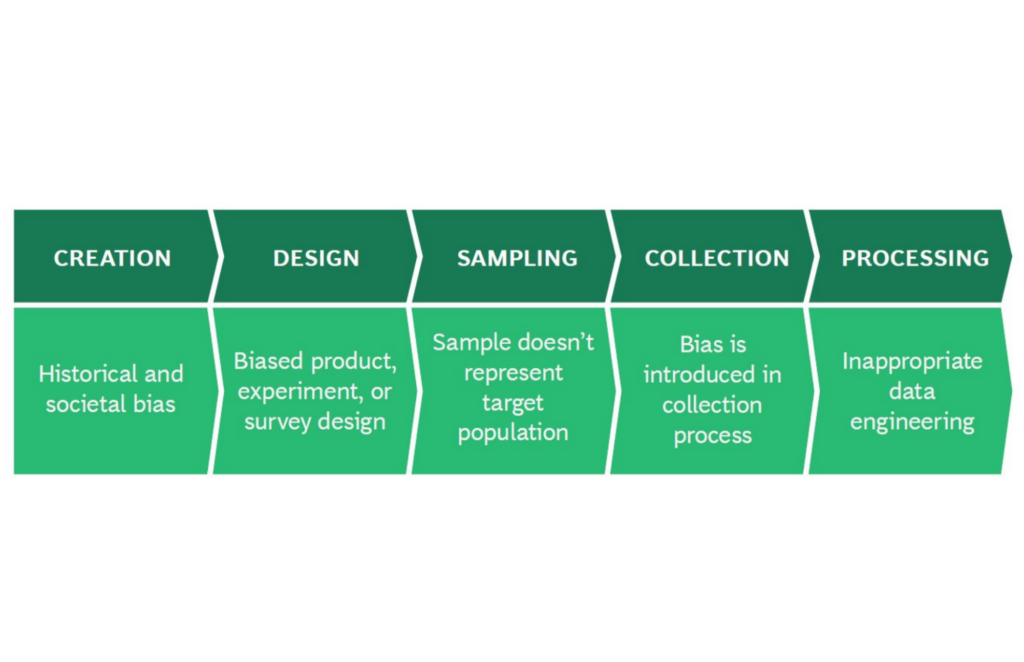
Source: Getting to the Root of Data Bias in AI
Recognize Intersectional Systems
There are multiple and interconnected forms of discrimination that contribute to bias and can perpetuate harm in the communities they are trying to positively impact. This includes identity at the crossroads of race, class, gender, sexuality, and age just to name a few. It’s important to understand the experiences of vulnerable communities at these crossroads in order to design a data lifecycle that protects their wellbeing.
Mind the Gap
There is a gap between what people experience in their day-to-day practice and the data that is collected on them. Never take data at face value. Scrutinize the data and try to understand if it truly reflects the lived experiences of those it purports to represent.
Unpack “Risk” and Center Impact
Establish time to think through potential unintended effects of the project and how it may impact people. Were assumptions made about the intended audience? What kind of unintended consequences could these assumptions have? How does this affect data sampling, collection, or implementation? Taking the time to consider these elements will help mitigate bias and make the project more equitable.
Algorithms Project Existing Biases Into the Future
Finally, remember that algorithms are built on data reflecting a particular time, place, and experience. Outputs for algorithms are only as good as the inputs used to design them. Data that’s inherently biased can project these biases and inaccuracies into the future. This risks hampering well-meaning attempts to positively impact systems and communities.
Six Types of Data Bias
While this list is far from exhaustive, data bias can present itself in six critical ways:
- 1. Reporting bias – not reporting on all available information. This bias could be due to coding issues or other difficulties in locating the required data.
- 2. Automation bias – favoring data or information derived from automated systems at the expense of non-automated data sources.
- 3. Selection bias – sampled population does not represent the true population. This bias can manifest itself in three key ways:
- > Sampling bias — lack of randomization in data collection.
- > Convergence bias — data not being collected in a representative manner. For example, surveying respondents who only have successfully completed a service journey and not including those who haven’t.
- > Participation bias — certain groups did not participate in the data collection process.
- 4. Overgeneralization bias – assuming that the information found in one data set will be representative of all data sets that are assessing the same information, regardless of the sample size.
- 5. Group attribution bias – standardizing the behavior of individuals to represent those of a group. This can result in furthering harmful stereotypes.
- 6. Implicit bias – making decisions based on personal assumptions and experiences. This is more commonly known as confirmation bias or experimenter’s bias, where data is used to fit preconceived notions.
Always Working to Minimize Bias
As data becomes a vital part of how government makes decisions, eliminating data bias will be an increasingly important priority. Totally eliminating data bias is an unachievable goal, as everyone makes mistakes. However, intentionality and awareness will minimize issues and inconsistencies. Incorporating team trainings and workshops, along with bias mitigating strategies, can help to ensure that data bias is always top of mind and that teams are taking tangible steps in making data work for everyone.
Carlos Andrés Arias is a Program Manager for the Beeck Center’s Data Labs: Roadmap to Recovery program.